
CrowdStrike: logicafout zorgde voor blue screen of death bij computers
De wereldwijde computerstoring is veroorzaakt door een logicafout, zo stelt securitybedrijf CrowdStrike in een analyse. Het bedrijf bracht gisteren een routine configuratie-update uit voor de Falcon-beveiligingssoftware. "Deze configuratie-update veroorzaakte een logicafout die op getroffen systemen tot een systeemcrash en blue screen of death (BSOD) leidde", aldus de analyse.
CrowdStrike laat weten dat het dergelijke updates meerdere keren per dag uitbrengt om op nieuwe tactieken, technieken en procedures van cybercriminelen te reageren. De gewraakte update was bedoeld om nieuwe, malafide named pipes gebruikt door malware te detecteren. "De configuratie-update veroorzaakte een logicafout die voor een crash van het besturingssysteem zorgde." Hoe de logicafout zich precies kon voordoen wordt nog onderzocht.
Op X en Hacker News wordt gewezen naar de inhoud van de update, die voor een deel uit null values bestaat. Daarbij vragen veel mensen zich af hoe het bestand door de kwaliteitscontrole is gekomen.
Het minimum wat je toch wilt is dat updates geleidelijk worden uitgerold en dat er een noodknop is om dit proces te stoppen bij een dergelijke "logicafout".
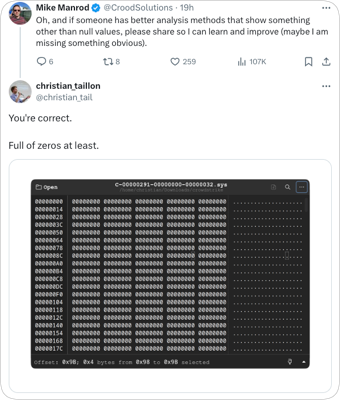
Het zijn Channel Files en degene met 291 zijn specifiek gerelateerd aan "Named Pipes"
Wel vreemd dat er zoveel nullen in staan.
Ongelofelijk dat een bedrijf met zo'n hoog technisch niveau zo iets de deur uit kan laten gaan.
Mag hopen dat een aantal managers een andere baan kunnen gaan zoeken.
"Elk aspect en facet denkbaar in automatisering, is 100% voorpelbaar, manipuleerbaar, voor iedere betrokkene...."
Zo ook :
De logicafout van 'crowdstrike'....
Niet testen!
De logicafout in de wereld van de automatiseerder die zijn getroffen?
Niet testen!
Zie de hele exercitie als een kwaliteitstest en je weet hoe Nederland er voor staat kwalitatief. #Bedroevend klaarblijkelijk.
ZO zie je maar weer dat commercie een groter gevaar is dan #cybercriminaliteit....
Daarom volgen we het principe van OTAP https://nl.wikipedia.org/wiki/OTAP
Een beetje spartelen en smoesjes heeft dan weing zin denk ik. Het is niet zo een klein beetje laf en zielig.
Als je de schade wereldwijd inschat, dan past het niet op je chequeboek denk ik. En ook niet meer op je scherm. Dus beter de deuren sluiten, de boeken ook. Zakelijk, intellectuele eigendom mag je niet uit de boedel onttrekken. Maar je kunt wel overnieuw beginnen met je mensen die wel wat kunnen. Want capaciteiten behoren niet tot de boedel.
Ik denk ook goede lab omgevingen opzetten. Want heel de wereld als je testplatform misbruiken mag wel een keertje over zijn. En dan zeggen, ja maar we hebben een updeet. Hallo.
Gebruikers/systeembeheerders zijn ook niet helemaal vrij van blaam:
- Blind vertrouwen op automatische updates
- Direct in productie uitrollen over alle PC's
- Creëren van een monocultuur waardoor alles omvalt
Daarom volgen we het principe van OTAP https://nl.wikipedia.org/wiki/OTAP
Daarom volgen we het principe van OTAP https://nl.wikipedia.org/wiki/OTAP
Die updates komen meerdere keren per dag volgens crowdstrike. Veel succes met Uw OTAP straat.
Daar zit denk ik, het grootste hiaat in het geheel. Crowdstrike is er alleen maar weer de zoveelste demo daarvan....
Daarom volgen we het principe van OTAP https://nl.wikipedia.org/wiki/OTAP
Daarom volgen we het principe van OTAP https://nl.wikipedia.org/wiki/OTAP
Die updates komen meerdere keren per dag volgens crowdstrike. Veel succes met Uw OTAP straat.
Het is geen obscuur geval wat alleen in specifieke configuraties een probleem is, want dan zouden er niet wijd en zijd zoveel computers plat zijn.
Ik dacht eerst "het gebeurt pas bij een reboot" maar dat kan ook niet want heel veel van die betrokken systemen worden niet regelmatig gereboot.
Afijn, prutswerk.
- Blind vertrouwen op automatische updates
- Direct in productie uitrollen over alle PC's
- Creëren van een monocultuur waardoor alles omvalt
Ik ken dat product niet maar het is niet zeker dat het wel door de locale beheerder instelbare features biedt voor een geleidelijke rollout.
Dat moet allemaal nog boven water komen.
Als het allemaal "voor uw bestwil en veiligheid zo snel mogelijk geinstalleerd wordt" (waar het op lijkt) dan treft alleen CrowdStrike de blaam, niet de lokale beheerders.
Dwz, "doe hem even uit en aan" (desnoods 15 keer).
Niet "start op in safe mode en gooi een bestand weg waarvan we je nog niet eens de exacte naam kunnen geven", dat kan de gemiddelde eindgebruiker op een laptop al niet eens, laat staan dat dit in een (semi-)embedded situatie "even" kan worden uitgevoerd.
Daarom volgen we het principe van OTAP https://nl.wikipedia.org/wiki/OTAP
Daarom volgen we het principe van OTAP https://nl.wikipedia.org/wiki/OTAP
Die updates komen meerdere keren per dag volgens crowdstrike. Veel succes met Uw OTAP straat.
En dat moet allemaal ongecontroleerd massaal over het hele computer-park uitgerold worden zodra die updastes er zijn?
Want dat is veilig? Als de leverancier (of iemand anders) maar roept: "Het is goed genoeg."
Ik zou me rot schamen als leidinggevende, security officer of beheerder die dit klakkeloos als procedure doorgevoerd hebben, zonder enig protest.
Dat zou dan minimaal een opdracht van en ondertekend door de directie moeten zijn, waarbij ze duidelijk hebben kunnen lezen wat de consequenties kunnen zijn. Geen: "wir habe es nicht gewusst" excuses toegestaan.
En dan ook nog geen goede (analoge) fallback oplossing hebben, als het een keer goed fout gaat.
Tenenkrommend.
Gaat er iets mis dan hoort er een veilige toestand te ontstaan. Terugval naar Windows defender zou automatisch moeten kunnen verlopen.
Gaat er iets mis dan hoort er een veilige toestand te ontstaan. Terugval naar Windows defender zou automatisch moeten kunnen verlopen.
You wonder how much more will shortly be updated of Crowdstrike's code, as iot is doubtful that the programmer created this (part of the) module didn't write any other part too...
beheerders willen niet verantwoordelijk zijn dat een stukje malware doorglipt in de week van testen en zijn blij dat de verantwoordelijkheid ligt bij een club, die nu dus blijkt, daar niet mee om kan gaan...
bootloop en bsod is een bijwerking die een 1ste weeks stagiare nog zou herkennen, binnen 1 dag.
Gaat er iets mis dan hoort er een veilige toestand te ontstaan. Terugval naar Windows defender zou automatisch moeten kunnen verlopen.
Bij een BSoD of een bootloop heb je ook heel weinig aan Windows Defender. Te weinig, te laat.
Teruggaan naar een herstelpunt gebeurde niet (automatisch), en werd ook niet geadviseerd.
Het betreffende programma controleerde haar eigen code of data ook niet op fouten (voor gebruik).
Wel kwam er het workdaround/advies om elke apparaat in safe mode te starten en een data-bestand (met een sys extentie) fysiek te verwijderen. Wat arbeidsintensief kan worden bij grote organisaties.
Hoe de definitieve fix werkt, is nog niet bekend gemaakt.
Dit had vookomen kunnen worden, door te testen. Zowel bij de leverancier als bij de klanten. Er zijn teveel machines "gelijktijdig" gecrasht, dat de fout niet op bestaande testomgevingen reproduceerbaar zou zijn. Ook vooraf.
En dat is er ook nog het gebrek aan analoge alternatieven, als zoiets als nu gebeurt. Bedrijven waren aan het spartelen.
Zou de bedrijfsschade (reputatie en financieel) nog steeds opwegen tegen de kosten van een analoog alternatief bij storing?
Gebruikers/systeembeheerders zijn ook niet helemaal vrij van blaam:
- Blind vertrouwen op automatische updates
- Direct in productie uitrollen over alle PC's
- Creëren van een monocultuur waardoor alles omvalt
https://www.dutchitchannel.nl/news/464047/erik-westhovens-crowdstrike-zal-moeten-onderzoeken-of-er-geen-sprake-is-van-supplychain-attack
In deze alerts zaten twee meldingen. de eerste dat er malicious content was gevonden (een infostealer) en de tweede dat er malicious connecties waren naar Ip adressen met een slechte reputatie. In de tijdlijn kan ik dan zien dat de alert getriggerd werd door de service. CSagent.sys was de eerste met de infostealer waarvan we nu weten dat het een false positive is. Het is gewoon functionaliteit van de system driver.
De tweede lijkt een downloader te zijn die content download van een delivery network. Echter lijkt het naar een IP adres met een bad reputation. Helaas kunnen we dat IP adres niet zien omdat de testmachines meteen een bluescreen geven en de sensor data dan weg is.
Crowdstrike zal zeker moeten gaan onderzoeken of er hier geen sprake is van een supplychain attack.
Ze zijn tot nu toe niet duidelijk in hoe het nou precies is misgegaan, dat onderzoeken ze nog, maar dan hoort ook tot de mogelijkheden dat er wel degelijk getest is maar dat het bestand is beschadigd tussen testen en publiceren. Als dat het is dan wordt kennelijk geen digitaal ondertekende checksum van de daadwerkelijk geteste versie van het bestand gebruikt om te controleren of wat uiteindelijk de deur uitgaat nog hetzelfde is, en is dat een punt waarop ze hun proces moeten verbeteren.
Ik weet niet of dit is hoe het zit, maar het is een mogelijkheid, en dat maakt het iets te vroeg om te concluderen dat er niet getest is, al is dat natuurlijk net zo goed een mogelijkheid. We moeten denk ik het onderzoek dat ze doen nog even afwachten om te horen wat er nou precies is gebeurd. En ik denk dat ze hun reputatie ernstig zouden beschadigen als ze niet open kaart zouden spelen, dus ik denk dat de kans best groot is dat ze ermee naar buiten treden.
Ik ken CrowdStrike en zijn leverancier verder niet, maar in het algemeen weet ik wel dat zelfs organisaties die hun zaakjes erg goed voor elkaar hebben altijd wel érgens iets hebben dat toch niet klopt. Mensen zijn veel beter in nadenken over hoe iets wel moet werken dan in nadenken over alle mogelijke manieren waarop er iets mis kan gaan. Er gaan af en toe dingen fout op een manier waar domweg niemand nog op was gekomen. Een goede organisatie leert al doende, documenteert wat ze leren, gebruikt die documentatie voortaan en wordt zo steeds professioneler. Maar ik betwijfel of er waar dan ook een organisatie ooit heeft bereikt dat ze absoluut feilloos zijn. En dit kan alles zijn van een schokkende blunder die dat bedrijf nooit had mogen maken tot een ongeluk dat in zo'n extreem klein hoekje zit dat het niet zo gek is dat ze er domweg nog niet op waren gekomen.
Crowdstrike zal zeker moeten gaan onderzoeken of er hier geen sprake is van een supplychain attack.
Dat zou een interessante attack zijn waarbij je hun systemen helemaal niet binnen hoeft te dringen, maar alleen afhankelijk bent van slecht testen.
Wellicht is het zelfs mogelijk de trigger afhankelijk te maken van de datum ofzo?
You wonder how much more will shortly be updated of Crowdstrike's code, as iot is doubtful that the programmer created this (part of the) module didn't write any other part too...
Complete write-up? Een paar regels open deur tekst.
Dit ziet er niet uit als een programmeerfout, in ieder geval niet in de programmacode zelf. Het lijkt op een fout in bestandcreatie (dataverwerking, build) of een datatransportfout.
https://www.crowdstrike.com/blog/falcon-update-for-windows-hosts-technical-details/
This is not related to null bytes contained within Channel File 291 or any other Channel File.
Lekker duidelijk weer. Het bestand bevat alleen maar null bytes en er zou een logic error zijn geweest in het updaten ervan, maar die null bytes hebben er niets mee te maken. Dat kan niet kloppen.
https://www.dutchitchannel.nl/news/464047/erik-westhovens-crowdstrike-zal-moeten-onderzoeken-of-er-geen-sprake-is-van-supplychain-attack
In deze alerts zaten twee meldingen. de eerste dat er malicious content was gevonden (een infostealer) en de tweede dat er malicious connecties waren naar Ip adressen met een slechte reputatie. In de tijdlijn kan ik dan zien dat de alert getriggerd werd door de service. CSagent.sys was de eerste met de infostealer waarvan we nu weten dat het een false positive is. Het is gewoon functionaliteit van de system driver.
De tweede lijkt een downloader te zijn die content download van een delivery network. Echter lijkt het naar een IP adres met een bad reputation. Helaas kunnen we dat IP adres niet zien omdat de testmachines meteen een bluescreen geven en de sensor data dan weg is.
Crowdstrike zal zeker moeten gaan onderzoeken of er hier geen sprake is van een supplychain attack.
Random memory dumps of upto 41004 bytes confirmed, it looks like a chunk of heap data was written to disk as .sys files during the update.
https://x.com/hackerfantastic/status/1814361018774237338
De bestanden AGmvan 41004 bytes zijn corrupt. Maar op hetzelfde tijdstip komen er ook goede bestanden uit van 35404 bytes.
Ze zijn tot nu toe niet duidelijk in hoe het nou precies is misgegaan, dat onderzoeken ze nog, maar dan hoort ook tot de mogelijkheden dat er wel degelijk getest is maar dat het bestand is beschadigd tussen testen en publiceren. Als dat het is dan wordt kennelijk geen digitaal ondertekende checksum van de daadwerkelijk geteste versie van het bestand gebruikt om te controleren of wat uiteindelijk de deur uitgaat nog hetzelfde is, en is dat een punt waarop ze hun proces moeten verbeteren.
Ik weet niet of dit is hoe het zit, maar het is een mogelijkheid, en dat maakt het iets te vroeg om te concluderen dat er niet getest is, al is dat natuurlijk net zo goed een mogelijkheid. We moeten denk ik het onderzoek dat ze doen nog even afwachten om te horen wat er nou precies is gebeurd. En ik denk dat ze hun reputatie ernstig zouden beschadigen als ze niet open kaart zouden spelen, dus ik denk dat de kans best groot is dat ze ermee naar buiten treden.
Ik ken CrowdStrike en zijn leverancier verder niet, maar in het algemeen weet ik wel dat zelfs organisaties die hun zaakjes erg goed voor elkaar hebben altijd wel érgens iets hebben dat toch niet klopt. Mensen zijn veel beter in nadenken over hoe iets wel moet werken dan in nadenken over alle mogelijke manieren waarop er iets mis kan gaan. Er gaan af en toe dingen fout op een manier waar domweg niemand nog op was gekomen. Een goede organisatie leert al doende, documenteert wat ze leren, gebruikt die documentatie voortaan en wordt zo steeds professioneler. Maar ik betwijfel of er waar dan ook een organisatie ooit heeft bereikt dat ze absoluut feilloos zijn. En dit kan alles zijn van een schokkende blunder die dat bedrijf nooit had mogen maken tot een ongeluk dat in zo'n extreem klein hoekje zit dat het niet zo gek is dat ze er domweg nog niet op waren gekomen.
Wat zorgelijk is, is dat dit wereldwijd veel grote systemen onderuit gehaald heeft. Waaronder ook ziekenhuizen.
En dat veel, zo niet alle, organisaties hier niet goed op voorbereid zijn.
“This is a good wake up call or a practice run for a major cyberattack,” Lisa Plaggemier, executive director of the non-profit National Cybersecurity Alliance, said Friday. “If we’re struggling this much with an outage from a major security provider, I mean, this is very much what a cyberattack would look like.”
https://www.politico.com/news/2024/07/19/white-house-it-outage-crowdstrike-00169799
Kan deze "oeps, foutje, bedankt" nog een keer gebeuren?
Ja, zeer zeker.
Kan dit altijd voorkomen worden?
Nee. Shit happens.
Zijn er (analoge) alternatieven als zoiets nog een keer gebeurt?
Ik vraag het me af, als ik naar gisteren kijk.
Wereldwijd stonden veel organisaties die getroffen zijn, met hun broek op hun enkels maar wat te hannessen.
Hebben of gaan we als mensheid hier leergeld uit trekken?
Ik vraag het me af. Maar hoop doet leven.
De wonderen zijn de wereld nog niet uit.
Ze zijn tot nu toe niet duidelijk in hoe het nou precies is misgegaan, dat onderzoeken ze nog, maar dan hoort ook tot de mogelijkheden dat er wel degelijk getest is maar dat het bestand is beschadigd tussen testen en publiceren. Als dat het is dan wordt kennelijk geen digitaal ondertekende checksum van de daadwerkelijk geteste versie van het bestand gebruikt om te controleren of wat uiteindelijk de deur uitgaat nog hetzelfde is, en is dat een punt waarop ze hun proces moeten verbeteren.
Ik weet niet of dit is hoe het zit, maar het is een mogelijkheid, en dat maakt het iets te vroeg om te concluderen dat er niet getest is, al is dat natuurlijk net zo goed een mogelijkheid. We moeten denk ik het onderzoek dat ze doen nog even afwachten om te horen wat er nou precies is gebeurd. En ik denk dat ze hun reputatie ernstig zouden beschadigen als ze niet open kaart zouden spelen, dus ik denk dat de kans best groot is dat ze ermee naar buiten treden.
Ik ken CrowdStrike en zijn leverancier verder niet, maar in het algemeen weet ik wel dat zelfs organisaties die hun zaakjes erg goed voor elkaar hebben altijd wel érgens iets hebben dat toch niet klopt. Mensen zijn veel beter in nadenken over hoe iets wel moet werken dan in nadenken over alle mogelijke manieren waarop er iets mis kan gaan. Er gaan af en toe dingen fout op een manier waar domweg niemand nog op was gekomen. Een goede organisatie leert al doende, documenteert wat ze leren, gebruikt die documentatie voortaan en wordt zo steeds professioneler. Maar ik betwijfel of er waar dan ook een organisatie ooit heeft bereikt dat ze absoluut feilloos zijn. En dit kan alles zijn van een schokkende blunder die dat bedrijf nooit had mogen maken tot een ongeluk dat in zo'n extreem klein hoekje zit dat het niet zo gek is dat ze er domweg nog niet op waren gekomen.
Ehm, en configuratiebestand of een datadefinitie-bestand hoort niet gierend een heel serverpark tot stitstand te brengen. dan gaan er meerdere dinggen goed fout.
Juist bij (grote) organisaties die 24/7 up moeten zijn, zoals luchthavens, vliehtuigmaatschappijen, ziekenhuizen, etc verwacht je dat de servers in clusters staan en steed machine voor machine (binnen dat cluster) geupdate wordt. Juist om niet het hele cluster in een keer onderuit te trekken of te laten crashen, zodat de dienstverlening door kan blijven gaan. Dit geldt ook voor de servers die de virtuele desktops aanbieden.
Gecontroleerde uitrol via WSUS, en ingrijpen als het op een server (of de eerste severs) fout gaat.
Dat is proven practice.
En als het allemaal niet meer bij te benen valt, dan zal er nagedacht moeten worden of de huidige opstelling nog wel werkbaar is.
Misschien is het tijd voor een extra gehard OS met bijbehorende hardware?
Verander de regels. Maak van het dagelijkse damspel met de hackers, een schaakspel of shogi.
https://www.dutchitchannel.nl/news/464047/erik-westhovens-crowdstrike-zal-moeten-onderzoeken-of-er-geen-sprake-is-van-supplychain-attack
In deze alerts zaten twee meldingen. de eerste dat er malicious content was gevonden (een infostealer) en de tweede dat er malicious connecties waren naar Ip adressen met een slechte reputatie. In de tijdlijn kan ik dan zien dat de alert getriggerd werd door de service. CSagent.sys was de eerste met de infostealer waarvan we nu weten dat het een false positive is. Het is gewoon functionaliteit van de system driver.
De tweede lijkt een downloader te zijn die content download van een delivery network. Echter lijkt het naar een IP adres met een bad reputation. Helaas kunnen we dat IP adres niet zien omdat de testmachines meteen een bluescreen geven en de sensor data dan weg is.
Crowdstrike zal zeker moeten gaan onderzoeken of er hier geen sprake is van een supplychain attack.
Blue screen of death betekent dat Windows niet start en dan heb je ook geen netwerk dat werkt.
Lees over:
https://help.shodan.io/integrations/logscale-ingest-api
Het probleem zat kennelijk in een configuratiebestand (ondanks de extensie .sys) van een groep "channel files" waar meerdere keren per dag updates in worden aangebracht om direct op nieuwe dreigingen te kunnen reageren. Dan is er weinig tijd om bij klanten te testen.
Nee, er zijn geen nieuwe dreigingen waar je binnen een minuut op moet reageren.
Het is "goed genoeg" als je uitrol in fases gebeurt. En uiteindelijk dan na een uur of 4 tot stand komt.
Stuur de updates eerst naar een set testmachines, dan naar de machines in je eigen bedrijf, dan naar machines bij een stuk of 10 klanten die vrijwillger zijn voor betatest (het product gratis krijgen als vergoeding), enzo breid je de cirkel steeds verder uit tot je uiteindelijk de hele wereld update.
Gaat er voor die tijd wat mis dan zit er in je controlroom een grote rode knop waarmee je de uitrol kunt stoppen. Geen Windows computer waarin je een programma moet starten, natuurlijk.
Als je op die testsystemen problemen ziet, of als je om je heen bij alle collega's de schermen blauw ziet worden, of gaat ineens de telefoon, dan druk je op de rode knop. En ga je rustig uitzoeken wat er mis is.
Ze zijn tot nu toe niet duidelijk in hoe het nou precies is misgegaan, dat onderzoeken ze nog, maar dan hoort ook tot de mogelijkheden dat er wel degelijk getest is maar dat het bestand is beschadigd tussen testen en publiceren. Als dat het is dan wordt kennelijk geen digitaal ondertekende checksum van de daadwerkelijk geteste versie van het bestand gebruikt om te controleren of wat uiteindelijk de deur uitgaat nog hetzelfde is, en is dat een punt waarop ze hun proces moeten verbeteren.
Ik weet niet of dit is hoe het zit, maar het is een mogelijkheid, en dat maakt het iets te vroeg om te concluderen dat er niet getest is, al is dat natuurlijk net zo goed een mogelijkheid. We moeten denk ik het onderzoek dat ze doen nog even afwachten om te horen wat er nou precies is gebeurd. En ik denk dat ze hun reputatie ernstig zouden beschadigen als ze niet open kaart zouden spelen, dus ik denk dat de kans best groot is dat ze ermee naar buiten treden.
Ik ken CrowdStrike en zijn leverancier verder niet, maar in het algemeen weet ik wel dat zelfs organisaties die hun zaakjes erg goed voor elkaar hebben altijd wel érgens iets hebben dat toch niet klopt. Mensen zijn veel beter in nadenken over hoe iets wel moet werken dan in nadenken over alle mogelijke manieren waarop er iets mis kan gaan. Er gaan af en toe dingen fout op een manier waar domweg niemand nog op was gekomen. Een goede organisatie leert al doende, documenteert wat ze leren, gebruikt die documentatie voortaan en wordt zo steeds professioneler. Maar ik betwijfel of er waar dan ook een organisatie ooit heeft bereikt dat ze absoluut feilloos zijn. En dit kan alles zijn van een schokkende blunder die dat bedrijf nooit had mogen maken tot een ongeluk dat in zo'n extreem klein hoekje zit dat het niet zo gek is dat ze er domweg nog niet op waren gekomen.
Ehm, en configuratiebestand of een datadefinitie-bestand hoort niet gierend een heel serverpark tot stitstand te brengen. dan gaan er meerdere dinggen goed fout.
Juist bij (grote) organisaties die 24/7 up moeten zijn, zoals luchthavens, vliehtuigmaatschappijen, ziekenhuizen, etc verwacht je dat de servers in clusters staan en steed machine voor machine (binnen dat cluster) geupdate wordt. Juist om niet het hele cluster in een keer onderuit te trekken of te laten crashen, zodat de dienstverlening door kan blijven gaan. Dit geldt ook voor de servers die de virtuele desktops aanbieden.
Gecontroleerde uitrol via WSUS, en ingrijpen als het op een server (of de eerste severs) fout gaat.
Dat is proven practice.
En als het allemaal niet meer bij te benen valt, dan zal er nagedacht moeten worden of de huidige opstelling nog wel werkbaar is.
Misschien is het tijd voor een extra gehard OS met bijbehorende hardware?
Verander de regels. Maak van het dagelijkse damspel met de hackers, een schaakspel of shogi.
Random memory dumps of upto 41004 bytes confirmed, it looks like a chunk of heap data was written to disk as .sys files during the update.
https://x.com/hackerfantastic/status/1814361018774237338
De bestanden AGmvan 41004 bytes zijn corrupt. Maar op hetzelfde tijdstip komen er ook goede bestanden uit van 35404 bytes.
Ongebruikte heap dan, want anders zijn het geen NUL bytes. Als er random data in de andere bestanden staat, waarom leidde die niet tot problemen en waarom meldt Crowdstrike daar niets over?
De heap bevat data die met het programma meekomt. Bijvoorbeeld strings of getallen. Zelfs als je initialiseerd met NUL bytes zullen er in de heap geheugen non-NUL bytes voorkomen. Het bestand lijkt te groot om er van uit te gaan dat het om ruimte tussen elementen gaat. Dit is ook niet erg duidelijk.
Dat is proven practice.
Wat je doet is de kans op ellende minimaliseren, maar zelfs met een heel kleine kans op ellende kom je soms toch stevig in de shit terecht. Je kan het niet volledig voorkomen, je kan er wel een zeldzaamheid van maken. En je bereikt op een gegeven moment een punt dat een minimale verdere verbetering alleen nog met explosie van de QA-kosten mogelijk zou zijn, of meer tijd kost dan je ervoor beschikbaar hebt. Dat maakt dat je de volle 100% zekerheid nooit gaat halen.
Er zijn dingen misgegaan in hoe de softwareindustrie zich heeft ontwikkeld die niet makkelijk terug te draaien zijn. Ooit, toen mainframes nog het dominante platform voor zakelijke verwerkingen waren en er nog geen internet was, ging gegevensuitwisseling via huurlijnen en tapes die door koeriers werden vervoerd. Er was een strikte scheiding tussen programma's en de door die programma's te verwerken gegevens. Je had geen fancy dingen als macro's in documenten die de scheiding tussen programma's en gegevens doorbreken, je had geen gegevenstypen die zo complex waren dat een bug in bijvoorbeeld een jpeg- of mpeg-library problemen kon geven. Gegevensbestanden bevatten data die veelal rechtstreeks, zonder conversies die bugs kunnen bevatten, door de processor konden worden verwerkt (mainframe-processoren kunnen met decimale getallen rekenen bijvoorbeeld).
Nu heb je een gigantische berg complexiteit erbij, en in complexiteit zitten fouten, we maken als mensen voortdurend dingen die complexer zijn dan we zelf aankunnen. En we hebben het internet, waar vorig jaar 5,44 miljard mensen toegang toe hadden wereldwijd. Dat is inclusief alle mensen die die fouten weten te misbruiken en die eindeloos veel slimmer en kundiger zijn dan jij en ik en onze collega's, en ook inclusief alle mensen die de software en diensten van die groep weer afneemt om nare dingen mee te doen. En dat zijn er veel, en ze staan allemaal vlak voor je digitale voordeur.
Als we verstandig zouden zijn zouden we als mensheid stapjes terug doen. Rot op met dat internet. Rot op met hypercomplexe documenttypen die macro's kunnen bevatten. Rot op met pc's waar allemaal mensen die in de verste verte niet snappen wat ze doen toch zelf software op kunnen installeren, ga terug naar alleen maar professioneel beheerde systemen met no-nonsense besturingssystemen zonder grafische gimmicks. Dat zou vreselijk veel ellende elimineren. Maar zie jij dat gebeuren? Los van dat het een mega-operatie zou zijn waarin gegarandeerd ook weer een hoop misgaat zie ik een wereldwijde opstand uitbreken als we het zouden proberen. En ik zou zelf ook een hoop gaan missen.
En dus leven we in een wereld die niet ideaal is, precies omdat die zoveel fraais bevat. Ik zie geen makkelijke oplossingen daarvoor.
Some people report that the files responsible for the CrowdStrike crashes (Eg. C-00000291-00000000-00000032.sys) are full of zeroes. This is not the case for any of the machines I fixed by hand today. One example is ad492bc8b884f9c9a5ce0c96087e722a2732cdb31612e092cdbf4a9555b44362. (on @virustotal)
Bevestigd door Costin Raiu: https://x.com/craiu/status/1814339965347610863
Costin Raiu is alom gerespecteerde malware researcher met 30 jaar antivirus ervaring.
Het begint met AA AA AA AA dat zou een "magic number" voor dit type van bestanden kunnen zijn.
En er staan allerlei 32-bit waarden in, sommige negatief.
Maar dit kan heel goed het gecompileerde "programma" voor die virusscanner zijn.
Het triggert een bug in de scanner, dat is duidelijk. Maar het is niet duidelijk dat de file corrupt is, en als dat wel zo zou zijn dan is die scanner nog steeds even brak als ie nu gebleken is te zijn.
Bevestigd door Costin Raiu: https://x.com/craiu/status/1814339965347610863
Costin Raiu is alom gerespecteerde malware researcher met 30 jaar antivirus ervaring.
Dat is inderdaad de Hash van C-00000291-00000000-00000032.sys met lengte 41004 bytes als corrupt bestand, maar van ditzelfde bestand zijn meerdere versies uitgekomen.
Er is ook 1 versie die allemaal 0-en bevat.
Ook is er een goed exemplaar met onderstaande SHA-256 op VirusTotal
e84f66e2fe2c44ee244db4ee2e0cf04413e8f6d171df56870d9aca96131ed526 met een lengte van 35404 bytes.
Er zijn dus nu al 3 varianten van C-00000291-00000000-00000032.sys in omloop.
Dat is proven practice.
Wat je doet is de kans op ellende minimaliseren, maar zelfs met een heel kleine kans op ellende kom je soms toch stevig in de shit terecht. Je kan het niet volledig voorkomen, je kan er wel een zeldzaamheid van maken. En je bereikt op een gegeven moment een punt dat een minimale verdere verbetering alleen nog met explosie van de QA-kosten mogelijk zou zijn, of meer tijd kost dan je ervoor beschikbaar hebt. Dat maakt dat je de volle 100% zekerheid nooit gaat halen.
Er zijn dingen misgegaan in hoe de softwareindustrie zich heeft ontwikkeld die niet makkelijk terug te draaien zijn. Ooit, toen mainframes nog het dominante platform voor zakelijke verwerkingen waren en er nog geen internet was, ging gegevensuitwisseling via huurlijnen en tapes die door koeriers werden vervoerd. Er was een strikte scheiding tussen programma's en de door die programma's te verwerken gegevens. Je had geen fancy dingen als macro's in documenten die de scheiding tussen programma's en gegevens doorbreken, je had geen gegevenstypen die zo complex waren dat een bug in bijvoorbeeld een jpeg- of mpeg-library problemen kon geven. Gegevensbestanden bevatten data die veelal rechtstreeks, zonder conversies die bugs kunnen bevatten, door de processor konden worden verwerkt (mainframe-processoren kunnen met decimale getallen rekenen bijvoorbeeld).
Nu heb je een gigantische berg complexiteit erbij, en in complexiteit zitten fouten, we maken als mensen voortdurend dingen die complexer zijn dan we zelf aankunnen. En we hebben het internet, waar vorig jaar 5,44 miljard mensen toegang toe hadden wereldwijd. Dat is inclusief alle mensen die die fouten weten te misbruiken en die eindeloos veel slimmer en kundiger zijn dan jij en ik en onze collega's, en ook inclusief alle mensen die de software en diensten van die groep weer afneemt om nare dingen mee te doen. En dat zijn er veel, en ze staan allemaal vlak voor je digitale voordeur.
Als we verstandig zouden zijn zouden we als mensheid stapjes terug doen. Rot op met dat internet. Rot op met hypercomplexe documenttypen die macro's kunnen bevatten. Rot op met pc's waar allemaal mensen die in de verste verte niet snappen wat ze doen toch zelf software op kunnen installeren, ga terug naar alleen maar professioneel beheerde systemen met no-nonsense besturingssystemen zonder grafische gimmicks. Dat zou vreselijk veel ellende elimineren. Maar zie jij dat gebeuren? Los van dat het een mega-operatie zou zijn waarin gegarandeerd ook weer een hoop misgaat zie ik een wereldwijde opstand uitbreken als we het zouden proberen. En ik zou zelf ook een hoop gaan missen.
En dus leven we in een wereld die niet ideaal is, precies omdat die zoveel fraais bevat. Ik zie geen makkelijke oplossingen daarvoor.
Toen er een wereldwijd ernstig probleem was met Apache Log4j, gebruikt door elke grote onderneming, ging er opvallend weinig mis. Hoe zou dat komen?
- Blind vertrouwen op automatische updates
- Direct in productie uitrollen over alle PC's
- Creëren van een monocultuur waardoor alles omvalt
Ik ken dat product niet maar het is niet zeker dat het wel door de locale beheerder instelbare features biedt voor een geleidelijke rollout.
Dat moet allemaal nog boven water komen.
Als het allemaal "voor uw bestwil en veiligheid zo snel mogelijk geinstalleerd wordt" (waar het op lijkt) dan treft alleen CrowdStrike de blaam, niet de lokale beheerders.
Het bestand ziet er uit als een object file voor door de programmeur gedefinieerde variabelen. Maar niet met het gebruikelijke magic number voor COFF bestanden als header (bv 4C 01). Een proprietary format ligt wel voor de hand.
Omdat het een antivirus programma is en er geen false positives moeten kunnen ontstaan door scanners is de data (non-standaard) geëncodeerd. Als de data ongecodeerd zou zijn, kan het bestand zelf "herkend" worden als malware.
Er staan diverse gedeeltelijke alfabet strings in, met een vreemde combinatie van hoofd en kleine letters. Een alfabet wordt wel eens gebruikt voor encoding/decoding.
Bestanden met alleen NULs (geen sample van) zijn moeilijker te verklaren. Mogelijk is er een tweede fout met een mislukte herstel release. Of een sabotagepoging van een aanvaller. Beide mogelijkheden zouden onderzocht moeten worden.
Vervolgens heeft hij een eigen bedrijf opgericht, dat dan overgenomen werd door McAfee.
Werd dan CTO bij McAfee. En daar is toen ook al een grote storing geweest met de antivirusscanner die tienduizenden computers liet crashen. In 2012 richt hij Crowdstrike op. In plaats van zich te focussen op het elimineren van virussen, wou hij nu het verdachte gedrag op een computer monitoren.
Met Crowdstrike zijn er crashes geweest op Debian, waarbij de computers weigerden te starten. Het is een hele kunsttoer om een Linux te doen crashen. Verder deden zulke crashes zich ook voor bij Red Hat Linux.
Dus Crowdstrike is niet aan zijn proefstuk toe. Iemand die een trial deed van Crowdstrike op Windows meldde dat 8 van zijn 65 computers compleet moesten gereïmaged worden, dus zag hij af van het programma.
Verleden jaar werd een deel van de testgroepen en ontwikkelaars ontslagen.
Op de koop toe pocht Crowdstrike ermee dat ze malware kunnen detecteren in 4 min. tegenover 24 min. bij Bitdefender en Microsoft. Met een aftelklok alsjeblief : https://www.crowdstrike.com/why-crowdstrike/mitre-attack-evaluation-results/
En op 15 juli jongstleden lanceerde hij een nieuwe versie van Falcon, waarbij door AI verzamelde gegevens over nieuwe dreigingen nu geïntegreerd werden in het product om zo snel mogelijk te kunnen reageren :
https://www.emerce.nl/wire/crowdstrike-falcon-complete-nextgen-mdr-zet-nieuwe-standaard-managed-detection-and-response
https://www.crowdstrike.com/press-releases/crowdstrike-falcon-complete-next-gen-mdr-sets-the-new-standard-for-managed-detection-and-response/
Mijn vermoeden is dat de CEO zo vlug mogelijk zijn nieuwe speeltje aan de wereld wou tonen, en zijn personeel onder druk zette om het zo vlug mogelijk te implementeren. Het .sys-bestand is een definitiebestand dat automatisch in de System32\CrowdStrike folder terechtkomt, en het deed automatisch de csagent crashen, die opstart voordat Windows start, als een rootkit eigenlijk.
Vermits testers en ontwikkelaars ontslagen waren in 2023, was er nu geen safeguard meer om het rampscenario tegen te houden. Onvoldoende getest bij Crowdstrike, en geen tests bij de firma's die het gebruiken, met het gekende gevolg.
Tenzij - zoals hierboven aangehaald - het gaat om malware die binnengesluisd werd bij Crowdstrike, zoals met SolarWinds gebeurde, wat de beurskoers van Crowdstrike allicht richting afgrond zou doen gaan.
Dit zijn de herstelmaatregelen die Crowdstrike rijkelijk laat publiek maakte, nadat ze in het begin al hun klanten verplicht hadden eerst in te loggen op hun supportportaal (zodat iedereen naar Reddit r/sysadmin of r/crowdstrike ging om uit te zoeken hoe dit op te lossen) :
https://www.crowdstrike.com/falcon-content-update-remediation-and-guidance-hub/
Misschien is het nu tijd om mijn Bitlocker herstelsleutel nog eens extra op te slaan op usb, als ik lees wat voor problemen dit veroorzaakte.
Ik heb medelijden met al die mensen die overal ter wereld in luchtvaarthallen gestrand zijn, en zelf grote kosten moeten dragen voor logies of de thuisreis, wat slechts voor een stuk of helemaal niet zal gecompenseerd worden door de touroperators. Of alle burgers die niet terechtkonden in ziekenhuizen, of hulpcentrales die verstoord werden. De uitval beperkt zich niet tot de getroffen bedrijven, maar strekt zich uit over honderdduizenden burgers wereldwijd.
Crowd strike : de menigte slaan. Dat is hier wel goed gelukt.
Bevestigd door Costin Raiu: https://x.com/craiu/status/1814339965347610863
Costin Raiu is alom gerespecteerde malware researcher met 30 jaar antivirus ervaring.
Dat is inderdaad de Hash van C-00000291-00000000-00000032.sys met lengte 41004 bytes als corrupt bestand, maar van ditzelfde bestand zijn meerdere versies uitgekomen.
Er is ook 1 versie die allemaal 0-en bevat.
Ook is er een goed exemplaar met onderstaande SHA-256 op VirusTotal
e84f66e2fe2c44ee244db4ee2e0cf04413e8f6d171df56870d9aca96131ed526 met een lengte van 35404 bytes.
Er zijn dus nu al 3 varianten van C-00000291-00000000-00000032.sys in omloop.
De volgende 3 bestanden in VirusTotal zijn ook 41004 bytes waarmee een BSOD wordt veroorzaakt.
edd47ba0047a291b1155af7b14bea92659a39b7db5b751eaa4f79e9df8f62987 C-00000291-00000000-00000012.sys
9d001ef3206fe2f955095244e6103ad7f8f318c7c5cbd91a0dd1f33e4217fcb2 C-00000291-00000000-00000034.sys
8ff578bc8d4682d5fa05a8b2addf0eb4f51ffb65f43c8e00821271e7949daedc C-00000291-00000000-00000049.sys
We weten niet hoe dit probleem er in gekomen is en dat is interessant om te horen nadat dit goed onderzocht is, maar het enige wat nu als een paal boven water staat en nooit ontkend kan worden is dat er niet wordt getest.
Als er was getest, bijvoorbeeld via een gefaseerde rollout die gestopt was bij problemen, was dit niet gebeurd.
Een monocultuur zet je niet zomaar even uit, helaas. Dat is niet simpel. En helaas zijn er maar al te veel mensen die besluiten voor een bepaald platform te gaan omdat ze denken dat het hun de kop niet zal kosten. Dat gedrag vermijdt geen monoculturen, dat gedrag creëert monoculturen, want zoals zij het benaderen is de veiligste aankoop wat iedereen al aankoopt. Ooit was het mantra dat niemand ooit ontslagen is voor het kopen van IBM, later is IBM daarin vervangen door Microsoft, en we zitten nu nog steeds met een enorme hoeveelheid bedrijven, overheden, andere organisaties en individuen die dat nu als legacy hebben.
Maar weet je wat er was gebeurd als Microsoft niet per ongeluk op het juiste moment met de juiste dingen bezig was geweest zodat ze in die positie konden komen? Dan had simpelweg een ander bedrijf dat vergelijkbaar opereert de markt weten te veroveren, een bedrijf dat nu net achter het net heeft gevist, vermoedelijk niet meer bestaat en waar we mogelijk zelfs nooit van gehoord hebben. Als het net iets anders was gelopen hadden we nu nooit van Micro Soft (oorspronkelijke schrijfwijze) gehoord en soortgelijke problemen met een ander platform gehad. Dit heeft iets te maken met hoe mensen nou eenmaal functioneren, zowel degenen met psychopatische/narcistische trekjes die daarmee succes weten te krijgen, als de menigtes die dat niet herkennen en enthousiast gaan voor waar die eerste groep ze lekker voor weet te maken.
Dát is de reden dat ik mijn energie niet verspil aan voortdurend op Microsoft afgeven, al gebruik ik het zelf al een kwart eeuw niet meer. Als zij het niet waren geweest was het helaas een ander geweest. Ik was op zich liever lid geweest van een mensheid die niet zo achter de gecreëerde hypes aanholt zonder te herkennen wat die eigenlijk zijn, die het verstandige inzicht dat een monocultuur schadelijk is serieus had genomen en dus juist niet had gekozen voor wat de meerderheid ook kiest. Dan was Windows marginaal geweest, én iOS én Android, was Linux niet op de achtergrond een indrukwekkend veel gebruikt OS geworden maar hadden de BSD's meer gebruikers en ontwikkelaars getrokken, dan waren mensen niet massaal voor social media-platforms gevallen en dan had de wereld er nu heel anders uitgezien, en dan was interoperabiliteit met gedeelde standaards bereikt en niet met gedeelde leveranciers. Alleen zie ik mijn leven lang al dat mensen er wel massaal in tuinen en dat ze dat keer op keer op keer op keer op keer (etc.) opnieuw doen.
Je vergelijking met Android vind ik wat misplaatst. Voor zover het bij CrowdStrike servers waren die onderuit gingen: Android als server-OS zou nieuw voor me zijn. Voor zover het om een vergelijking met desktopsystemen gaat: tussen een smartphone/tablet en een desktopsysteem bestaat een belangrijk verschil. Een smartphone-app heeft zijn eigen storage en deelt heel weinig tot niets met andere apps. Dat is een belangrijke basis voor de beveiliging binnen smartphone-besturingssystemen. Op een desktop-besturingssysteem heb je bestanden die je met verschillende applicaties kan openen en ook vaak redenen om dat te doen (wil je die .jpg in een grafische viewer of in een tekenpakket openen deze keer?). Ook heb je bestanden niet gegroepeerd naar type of applicatie (al doet Microsoft erg zijn best met "My Documents" etc. om dat wel te doen), maar naar organisatie-onderdeel (afdeling, groep) en onderwerp, en per onderwerp kan je allerlei verschillende bestandstypes door elkaar hebben staan omdat die nou eenmaal bij dat onderwerp horen. Wat smartphones doen is een wezenlijk andere insteek, en ik moet er niet aan denken dat een werk-onderwerp over tig apps versnipperd opgeslagen is, dat wil ik bij elkaar zien.
Tijdens BSoD-koorts (Blue Screen of Death), veroorzaakt door CSAgent.sys (CrowdStrike Falcon Sensor Driver) , crashte mijn pc (Windows 10 versie 22H2 (10.0.19041.4651)) ook met BugCheck 0x50 (PAGE_FAULT_IN_NONPAGED_AREA) . Omdat dit een geweldige kans is, heb ik de kernelgeheugendump MEMORY.DMP geanalyseerd met WinDbg in het kader van mijn persoonlijke hobby (de analyseresultaten hebben niets te maken met de opvattingen van het bedrijf waarvoor ik werk, enz.)).
U kunt zien dat CSAgent.sys de oorzaak is door simpelweg de opdracht !analyze -v uit te voeren
!analyze -vDe opdracht csagent.syslaat zien dat de crash plaatsvond omdat de systeemwerkthread (dat wil zeggen de NT-kernel zelf) leestoegang had tot het ongeldige virtuele adres 0xfffa602`000000a2. Kortom, als u dit resultaat krijgt, heeft u
de oorzaak vrijwel geïdentificeerd:
Dit is terug te vinden, door te zoeken op:
https://komorih.wordpress.com/?s=csagent
Daarna het zoekresultaat selecteren, waarna het artikel volgt met de Post-datum:21/07/2024
Kortom, de code in csagent.sys veroorzaakt de fout en hier heb ik nog geen update van gezien.
Er is nu alleen een workaround doordat er weer goede 291 Channel files worden aangeboden.
Maar om de Root Cause aan te pakken moet er toch echt een nieuwe csagent.sys komen.
Die heb ik tot nog toe niet gezien.
Niet in de traditionele zin. Volgens Crowdstrike dient het het bestand voor de controle van named pipes. Het bevat variabelen, maar niet de traditionele zoekstrings of checksums.
Daarom volgen we het principe van OTAP https://nl.wikipedia.org/wiki/OTAP
Dus jouw productiesystemen gebruiken geen enkele externe resource?
OTAP is voornamelijk voor software ontwikkeling en is niet gerelateerd aan operationele stabiliteit.
We weten niet hoe dit probleem er in gekomen is en dat is interessant om te horen nadat dit goed onderzocht is, maar het enige wat nu als een paal boven water staat en nooit ontkend kan worden is dat er niet wordt getest.
Als er was getest, bijvoorbeeld via een gefaseerde rollout die gestopt was bij problemen, was dit niet gebeurd.
Kortom, de code in csagent.sys veroorzaakt de fout en hier heb ik nog geen update van gezien.
Er is nu alleen een workaround doordat er weer goede 291 Channel files worden aangeboden.
Maar om de Root Cause aan te pakken moet er toch echt een nieuwe csagent.sys komen.
Die heb ik tot nog toe niet gezien.
Dacht je nou echt dat Crowdstrike even in een weekend snel een update van csagent zou gaan verspreiden?
Nadat dit eerst fout gegaan is?
Nee, die gaan die driver nu eerst met een stofkammetje nakijken en dan een update uitbrengen waarvan ze "zeker" weten dat er niet meer dit soort fouten in zitten, en DAN pas gaan ze weer functionele definitiefiles uitbrengen.
Dat kan even duren, ze gaan echt niet sneller werken omdat jij zit mee te kijken!
We weten niet hoe dit probleem er in gekomen is en dat is interessant om te horen nadat dit goed onderzocht is, maar het enige wat nu als een paal boven water staat en nooit ontkend kan worden is dat er niet wordt getest.
Als er was getest, bijvoorbeeld via een gefaseerde rollout die gestopt was bij problemen, was dit niet gebeurd.
Daarvoor worden windows VM's gebruikt die on the fly worden gecreerd en weer vernietigd. Elke git commit (ja microsoft gebruikt git) van een software wijziging wordt getest. Als windows crasht krijg je de commit patch niet in de productie versie.
Windows crashte blijkbaar niet. Je zou je kunnen afvragen welke windows versie dan als virtual machine werd gebruikt in de pipeline en wat hebben al die gecrashte windows devices en VM's gemeenschappelijk. Dat zal moeten worden uitgezocht.
Ik gok dat het probleem patch dinsdag is met een niet meer backwards compatible windows kernel, die was een week eerder uitgerold met ontiegelijk veel windows issues waarvan kernel en Kernel-Mode Driver wijzigingen !! https://www.bleepingcomputer.com/news/microsoft/microsoft-july-2024-patch-tuesday-fixes-142-flaws-4-zero-days/
Het zou mij niet verbazen dat de gebruikte windows test VM nog niet die patches heeft gehad (was 1 week oud). Dat is ook het grote probleem met gesloten software, je kan niet testen tegen de actualiteit. Het ligt opeens op je bord i.t.t open source git repositories.
Reken maar dat er nu veel wordt gepraat tussen Microsoft en CrowdStrike en dat er uiteindelijk ook zaken afgekocht gaan worden.
We weten niet hoe dit probleem er in gekomen is en dat is interessant om te horen nadat dit goed onderzocht is, maar het enige wat nu als een paal boven water staat en nooit ontkend kan worden is dat er niet wordt getest.
Als er was getest, bijvoorbeeld via een gefaseerde rollout die gestopt was bij problemen, was dit niet gebeurd.
Hou maar op, als er iets wordt uitgerold wat 8.5 miljoen computers down brengt dan is er NIET getest.
Waar met getest uiteraard "deugdelijk getest" bedoeld wordt.
Er is geen test gedaan in de blijkbaar-veel-voorkomende situatie waarin het plat ging.
Tot nog toe heb ik daar nog geen goede verklaring van gezien.
We weten niet hoe dit probleem er in gekomen is en dat is interessant om te horen nadat dit goed onderzocht is, maar het enige wat nu als een paal boven water staat en nooit ontkend kan worden is dat er niet wordt getest.
Als er was getest, bijvoorbeeld via een gefaseerde rollout die gestopt was bij problemen, was dit niet gebeurd.
Hou maar op, als er iets wordt uitgerold wat 8.5 miljoen computers down brengt dan is er NIET getest.
Waar met getest uiteraard "deugdelijk getest" bedoeld wordt.
Er is geen test gedaan in de blijkbaar-veel-voorkomende situatie waarin het plat ging.
Tot nog toe heb ik daar nog geen goede verklaring van gezien.
Hou maar op, als er iets wordt uitgerold wat 8.5 miljoen computers down brengt dan is er NIET getest.
Waar met getest uiteraard "deugdelijk getest" bedoeld wordt.
Er is geen test gedaan in de blijkbaar-veel-voorkomende situatie waarin het plat ging.
Gezien het aantal getroffen systemen is er niet goed genoeg getest.
Als dit een probleem was wat ALLE of bijna alle Windows computers getroffen had (bijv iets via Windows Update of een update van een of andere Intel device driver oid) dan hadden we wel anders gepiept.
We weten niet hoe dit probleem er in gekomen is en dat is interessant om te horen nadat dit goed onderzocht is, maar het enige wat nu als een paal boven water staat en nooit ontkend kan worden is dat er niet wordt getest.
Als er was getest, bijvoorbeeld via een gefaseerde rollout die gestopt was bij problemen, was dit niet gebeurd.
Daarvoor worden windows VM's gebruikt die on the fly worden gecreerd en weer vernietigd. Elke git commit (ja microsoft gebruikt git) van een software wijziging wordt getest. Als windows crasht krijg je de commit patch niet in de productie versie.
Windows crashte blijkbaar niet. Je zou je kunnen afvragen welke windows versie dan als virtual machine werd gebruikt in de pipeline en wat hebben al die gecrashte windows devices en VM's gemeenschappelijk. Dat zal moeten worden uitgezocht.
Ik gok dat het probleem patch dinsdag is met een niet meer backwards compatible windows kernel, die was een week eerder uitgerold met ontiegelijk veel windows issues waarvan kernel en Kernel-Mode Driver wijzigingen !! https://www.bleepingcomputer.com/news/microsoft/microsoft-july-2024-patch-tuesday-fixes-142-flaws-4-zero-days/
Het zou mij niet verbazen dat de gebruikte windows test VM nog niet die patches heeft gehad (was 1 week oud). Dat is ook het grote probleem met gesloten software, je kan niet testen tegen de actualiteit. Het ligt opeens op je bord i.t.t open source git repositories.
Reken maar dat er nu veel wordt gepraat tussen Microsoft en CrowdStrike en dat er uiteindelijk ook zaken afgekocht gaan worden.
Deze posting is gelocked. Reageren is niet meer mogelijk.
Security Architect IT/OT
Als Security Architect IT/OT geef jij richting aan de technische en architec-tonische inrichting van veilige IT- en OT-omgevingen. Je vertaalt bestaand beleid en wet- en regelgeving naar concrete, uitvoerbare ontwerpprincipes en bewaakt de samenhang tussen techniek, organi-satie en risico’s.
Information Security Manager IT/OT
Als Information Security Manager IT/OT zorg jij ervoor dat informatiebeveiliging binnen onze IT- en OT-omgevingen niet alleen op papier klopt, maar aantoonbaar werkt in de uitvoering. Je richt je op het veilig en betrouwbaar functioneren van operationele processen en draagt bij aan een volwassen, risicogestuurde be-veiliging van onze vitale infrastructuur.
Security Analist IT/OT
Als Security Analist IT/OT draag jij bij aan het verder professionaliseren van onze digitale weerbaarheid. Je bewaakt da-gelijks de veiligheid van onze IT- en OT-omgevingen en zorgt ervoor dat risico’s tijdig worden gesignaleerd en opgevolgd. Zo help je mee om vitale processen rondom water en onze kantoorauto-matisering betrouwbaar en veilig te laten functioneren.
