
Onderzoek: zelfs de beste AI-chatbots hallucineren vaak
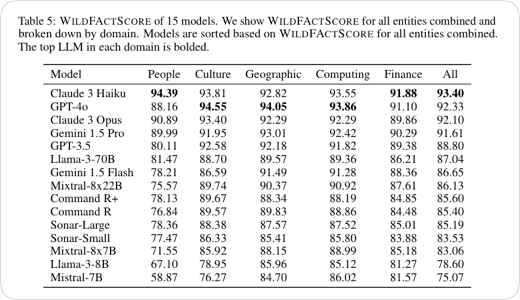
Zelfs de beste AI-chatbots hallucineren vaak, wat laat zien dat de uitvoer nog niet volledig is te vertrouwen, zo stellen onderzoekers van verschillende universiteiten en het Allen Institute for Artificial Intelligence. Voor hun onderzoek ontwikkelden de onderzoekers een benchmark genaamd WildHallucinations waarmee ze keken of wat AI-chatbots vertellen wel klopt. Voor het onderzoek moesten de AI-chatbots allerlei vragen beantwoorden die ook door gebruikers gesteld zouden kunnen worden (pdf).
Daarbij gebruikten de onderzoekers voor ongeveer van de helft van de vragen onderwerpen die geen Wikipedia-pagina hebben. De meeste AI-chatbots zijn getraind met Wikipedia-data. Eén van de taalmodellen die goed presteerde was Claude 3 Haiku, maar dat kwam mede doordat de chatbot maar 72 procent van de vragen beantwoordde. Vragen waarop de chatbot geen antwoord weet werden niet beantwoord. Daarnaast maakt ook het onderwerp veel uit. Zo blijkt taalmodel Mistral-7B bij het onderwerp 'mensen' in meer dan veertig procent van de antwoorden te hallucineren.
Volgens de onderzoekers is het hallucineren een probleem als gebruikers de uitvoer van de chatbots vertrouwen. "De belangrijkste conclusie van ons onderzoek is dat we de uitvoer van model generations nog niet volledig kunnen vertrouwen", zegt onderzoeker Wenting Zhao tegenover TechCrunch. "Op dit moment kunnen zelfs de beste modellen in slechts 35 procent van de gevallen hallucinatievrije tekst genereren."
Ben nog steeds bezig met mijn HAL9000.
Mensen zonder zelfkennis kunnen AI beter niet gebruiken. Ze waren al lui en negatief, verwachten dat dit nu eindelijk eens alles voor ze oplost. En dan willen ze er nog geld aan verdienen ook. Maar dat moet iemand anders maar voor ze oplossen dan. Omdat het voor die ander toch heel gemakkelijk is, iets met een app of zo, dus mag niks kosten ook.
AI is een heel geinig nieuw hulpmiddel. Maar je moet wel willen leren fietsen. Anders ga je op je bek.
Ben nog steeds bezig met mijn HAL9000.
We moeten tig keer tegen klanten van onze toepassingen zeggen dat we niet alle hallucinaties kunnen stoppen tenzij we de scope van het model aanzienlijk verkleinen. Vaak de teugels laten vieren betekent wel meer gevarieerde hallucinatie maar tegelijk ook minder vaak dat het voorkomt.
Je kunt dit zelf testen door een spelling check A.I te pakken. Gooi er een groot genoeg lap tekst in en je zult een loop gaan zien waarbij de A.I. een woord wil vervangen met een ander woord en vervolgens dat woord weer met het vorige woord wil vervangen. Beide kloppen technisch maar niet in gramaticale toepassing en als je de 1 verbied dan gaat er veel meer naar de knoppen. Dus je kiest voor 1 van de foute of je herschrijft het geheel.
Een beetje zoals je ook site metrics moet benaderen. Je kan giga er bovenop zitten, zodat je page speed etc. hoog is, maar als je 1 waarde dan heel laag hebt zitten wat je niet hoger kan krijgen door site functionaliteiten gaat je totaal gemiddelde hoe dan ook naar de knoppen. Of je kan genuanceerder optimaliseren waardoor het gemiddelde over de gehele linie hoger ligt. Eerste is natuurlijk technisch beter maar leg maar aan een klant uit waarom die gemiddelde 35% score toch echt beter is dan de 70%.die je ze door kan sturen.
Ik draai alleen offline software en AI-modellen gebaseerd op vrije software.
Mijn Tensor G2+8GB werkgeheugen kan het wel aardig aan met modellen tot 7B parameters.
Meestal draai ik niet hoger dan 4-5bit modellen, anders wordt het te traag.
Ook mijn Ryzen 5 4500U (integrated GPU) vind het wel okee zolang ik meer VRAM toewijs via de UMA framebuffer.
Daarnaast heb ik lekker snel 64GB werkgeheugen, (met vermindering van geheugen via de UMA framebuffer) en een snelle SSD.
Ook GNU/Linux gaat er goed mee om.
Daarnaast houd ik niet van censuur, dus draai ik ongecensureerde modellen, ik vindt het super irritant om in "discussie" te gaan met mijn computers om daar omheen te werken, als ik bijv. sappige grappen wil horen of de AI denkt dat ik iets serieus meen wil ik gewoon waar mijn computer voor bedoeld is; mijn commando's opvolgen, dat ding is er voor mij, niet andersom.
Type één zoek argument in met het trefwoord “wiki” toegevoegd en klik de zoeken knop. Dan zie je tussen de resultaten de wiki pagina in de top 10 en enkele tellen later begint copilot rechts op de pagina precies dezelfde data te “genereren”. Alleen dit AI resultaat is tot 7 keer meer energiebelastend dan de normale zoekfunctie.
Ik draai alleen offline software en AI-modellen gebaseerd op vrije software.
Mijn Tensor G2+8GB werkgeheugen kan het wel aardig aan met modellen tot 7B parameters.
Meestal draai ik niet hoger dan 4-5bit modellen, anders wordt het te traag.
Ook mijn Ryzen 5 4500U (integrated GPU) vind het wel okee zolang ik meer VRAM toewijs via de UMA framebuffer.
Daarnaast heb ik lekker snel 64GB werkgeheugen, (met vermindering van geheugen via de UMA framebuffer) en een snelle SSD.
Ook GNU/Linux gaat er goed mee om.
Daarnaast houd ik niet van censuur, dus draai ik ongecensureerde modellen, ik vindt het super irritant om in "discussie" te gaan met mijn computers om daar omheen te werken, als ik bijv. sappige grappen wil horen of de AI denkt dat ik iets serieus meen wil ik gewoon waar mijn computer voor bedoeld is; mijn commando's opvolgen, dat ding is er voor mij, niet andersom.
Precies! De verantwoordelijkheid moet bij gebruikers liggen en niet computers, zodra computers verantwoordelijkheden gaan dragen voor mensen en hetgeen dat mensen er mee doen is het eind zoek.
Er zjn gewoon wetten in plaats om het daadwerkelijk uitvoeren van fantasieën te voorkomen.
Anders zouden we ook horrorfilms moeten opzeggen, deze geven immers ook voorbeelden van bijv. geweld en gruwel, evenals lectuur zoals boeken.
Vrijheid van meningsuiting en spraak, en al helemaal n de privésfeer moet intact blijven.
Daarnaast is code als vrije spraak.
Geweldig hulpmiddel voor taalanalyse.
Heeft nog wat last van de Amerikaans-Engelse inregeling,
die het met de- en het-woorden wel eens te veel wordt,
concrete van abstracte voorbeelden te onderscheiden.
Geef het ontwikkeltijd. Hopelijk wordt het niet door
krachten achter de schermen gebruikt tegen hun product,
de consumerende mens via Big Commerce en IT.
#laufer
Deze man legt uit hoe een LLM intern werkt (nogal verhelderend) en hoe het tot een antwoord komt.
https://www.youtube.com/watch?v=7esIw6_FVf0
Voor een heleboel dingen is het leuk te gebruiken, maar erop vertrouwen is niet verstandig
Als je ziet wat sommige mensen vertellen over bepaalde niet aan stricte logica onderhevige onderwerpen dan vraag je je ook af hoe ze dat kunnen...
Als je kunstmatige intelligentie gaat ontwikkelen, moet dat dan lijken op menselijke intelligentie, of moet je een perfecte vraagbaak ontwikkelen die zich niet als een mens gedraagt?
Voor beiden zal wel iets te zeggen zijn, maar ik denk dat die 2e eerder als onbruikbaar en ongeloofwaardig gezien wordt dan die eerste...
Zodra we aan het taalgebruik gewend zijn.
Het was al eerder besloten de term KI alleen te gebruiken als het al bestaande medisch jargon, al hebben de meest psychotische ("hallucinerende") AI's wel degelijk hun charme. Kunnen inderdaad heel interessante conversaties mee gevoerd worden. Grote feitenkennis, zoals je van AI mag verwachten, al zijn de meesten nightly builds uit de garagebox. Maar zo zijn Gates en Jobs toch ook begonnen?
Deze man legt uit hoe een LLM intern werkt (nogal verhelderend) en hoe het tot een antwoord komt.
https://www.youtube.com/watch?v=7esIw6_FVf0
Bedankt! Dat is een erg goede presentatie!
Deze man legt uit hoe een LLM intern werkt (nogal verhelderend) en hoe het tot een antwoord komt.
https://www.youtube.com/watch?v=7esIw6_FVf0
Bedankt! Dat is een erg goede presentatie!
Deze man legt uit hoe een LLM intern werkt (nogal verhelderend) en hoe het tot een antwoord komt.
https://www.youtube.com/watch?v=7esIw6_FVf0
Bedankt! Dat is een erg goede presentatie!
Uiteindelijk weten mensen vaak (bij primaire reacties) ook niet wat ze zeggen. Maar beseffen naderhand wat ze gezegd hebben. Ik heb alleen ervaring met de chatfunctie van Bing (chatgpt), waarbij het mij vaak in een gesprekje lukt om door te bouwen op een onderwerp. Het taalmodel onthoudt blijkbaar wel waar het gesprek over gaat. En ik verbaas mij soms over de intelligentie waarmee het systeem gesprekken voert. Het heeft vast iets te maken met ten onrechte menselijke eigenschappen aan iets toe te schrijven.. Maar het kan ook dat we nog niet goed weten hoe een taalmodel werkt.
Uiteindelijk weten mensen vaak (bij primaire reacties) ook niet wat ze zeggen. Maar beseffen naderhand wat ze gezegd hebben. Ik heb alleen ervaring met de chatfunctie van Bing (chatgpt), waarbij het mij vaak in een gesprekje lukt om door te bouwen op een onderwerp. Het taalmodel onthoudt blijkbaar wel waar het gesprek over gaat. En ik verbaas mij soms over de intelligentie waarmee het systeem gesprekken voert. Het heeft vast iets te maken met ten onrechte menselijke eigenschappen aan iets toe te schrijven.. Maar het kan ook dat we nog niet goed weten hoe een taalmodel werkt.
Heldere uitleg idd. Over Gerben: Before that he was (amongst other things)
-Lead Architect of the Judiciary in The Netherlands:
-and Head of the forensic IT department of the Dutch Forensic Institute.
Misschien heeft hij ook een accountje bij meta.
IBM - 1
https://nos.nl/artikel/2534266-kunstmatige-intelligentie-beschuldigt-onschuldige-journalist-van-kindermisbruik
IBM - 1
https://nos.nl/artikel/2534266-kunstmatige-intelligentie-beschuldigt-onschuldige-journalist-van-kindermisbruik
Een betere naam voor chatgpt zou " Sir Guess a. Lot" zijn.
Vanwege het raadplegen van de random generator.
Deze posting is gelocked. Reageren is niet meer mogelijk.
Security Architect IT/OT
Als Security Architect IT/OT geef jij richting aan de technische en architec-tonische inrichting van veilige IT- en OT-omgevingen. Je vertaalt bestaand beleid en wet- en regelgeving naar concrete, uitvoerbare ontwerpprincipes en bewaakt de samenhang tussen techniek, organi-satie en risico’s.
Information Security Manager IT/OT
Als Information Security Manager IT/OT zorg jij ervoor dat informatiebeveiliging binnen onze IT- en OT-omgevingen niet alleen op papier klopt, maar aantoonbaar werkt in de uitvoering. Je richt je op het veilig en betrouwbaar functioneren van operationele processen en draagt bij aan een volwassen, risicogestuurde be-veiliging van onze vitale infrastructuur.
Security Analist IT/OT
Als Security Analist IT/OT draag jij bij aan het verder professionaliseren van onze digitale weerbaarheid. Je bewaakt da-gelijks de veiligheid van onze IT- en OT-omgevingen en zorgt ervoor dat risico’s tijdig worden gesignaleerd en opgevolgd. Zo help je mee om vitale processen rondom water en onze kantoorauto-matisering betrouwbaar en veilig te laten functioneren.
